TokenOptEnv
TokenOptEnv is an OpenEnv environment for CAMRE: a cost-aware meta-reasoning benchmark for code and log tasks. Agents do not just solve tasks. They also learn how to manage context, retrieval, memory, checkpoints, compression, and model-routing strategy under explicit token and cost budgets.
This repository captures the full hackathon story across both V1 and V2 of CAMRE.
- V1 establishes the core benchmark idea: explicit cache, compression, routing, and budget-aware decision-making instead of hidden middleware.
- V2 extends that foundation with bounded working memory, checkpoints, selective hydration, milestone shaping, and escalation-aware routing for longer-horizon tasks.
The current deployed runtime is the V2 environment, but the repo intentionally preserves the V1 notebook, earlier benchmark framing, and the evolution path between the two versions.
Version Overview
V1 Core Contributions
- explicit action space for reading artifacts, querying cache, compressing context, routing subtasks, and submitting answers
- deterministic graders and seeded task scenarios
- a real-world model catalog with simulated cost/quality behavior
- composite reward shaping around correctness, budget use, and routing decisions
V2 Extensions
- Bounded working memory so the agent cannot keep everything loaded forever.
- Explicit checkpoints so the agent must decide what facts to preserve before purging memory.
- Artifact handles and selective hydration so large/noisy artifacts are often previewed first and only the relevant segments are loaded into working memory.
- Cascade routing with confidence-based escalation so a weak route can be escalated to a stronger model only when it is justified.
- Milestone-based shaping so long-horizon tasks emit dense process rewards rather than only terminal outcomes.
Together, V1 and V2 make CAMRE much closer to the real systems problem the benchmark is trying to measure: not just solving a task, but solving it efficiently, strategically, and durably over long trajectories.
Benchmark Goals
CAMRE is designed to answer questions like:
- When should an agent read directly versus hydrate targeted evidence?
- When should it checkpoint knowledge before purging working memory?
- When should it query cache instead of recomputing?
- When should it compress context?
- When should it escalate from a cheap model to a stronger one?
The benchmark is deterministic enough for repeatable RL training and structured enough for decomposed reward analysis.
Project Links
- GitHub repository: Prathuvj/TokenOptEnv
- Environment Space: prathuvj/TokenOptEnv
- Training Space: prathuvj/CAMRE-Training
- Model repo: prathuvj/CAMRE-Qwen3.5-4B-GRPO-V2
Result Snapshots
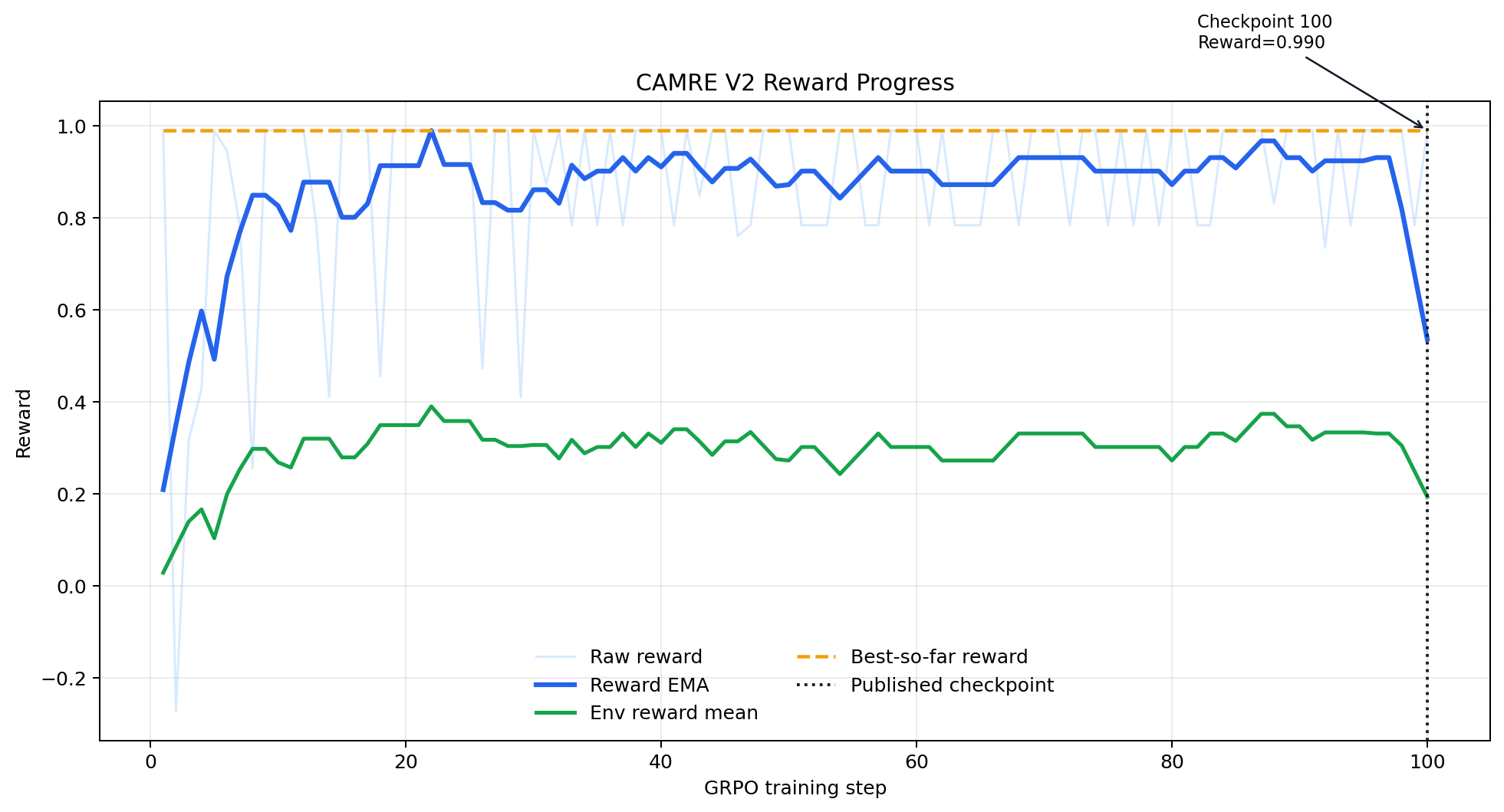
The current public training artifact is the step-100 export from the first stable CAMRE V2 GRPO run. That is the public checkpoint currently linked in the Spaces and model repo, but the broader project and benchmark narrative spans both the original V1 environment design and the later V2 long-horizon extension.
Reward Progress
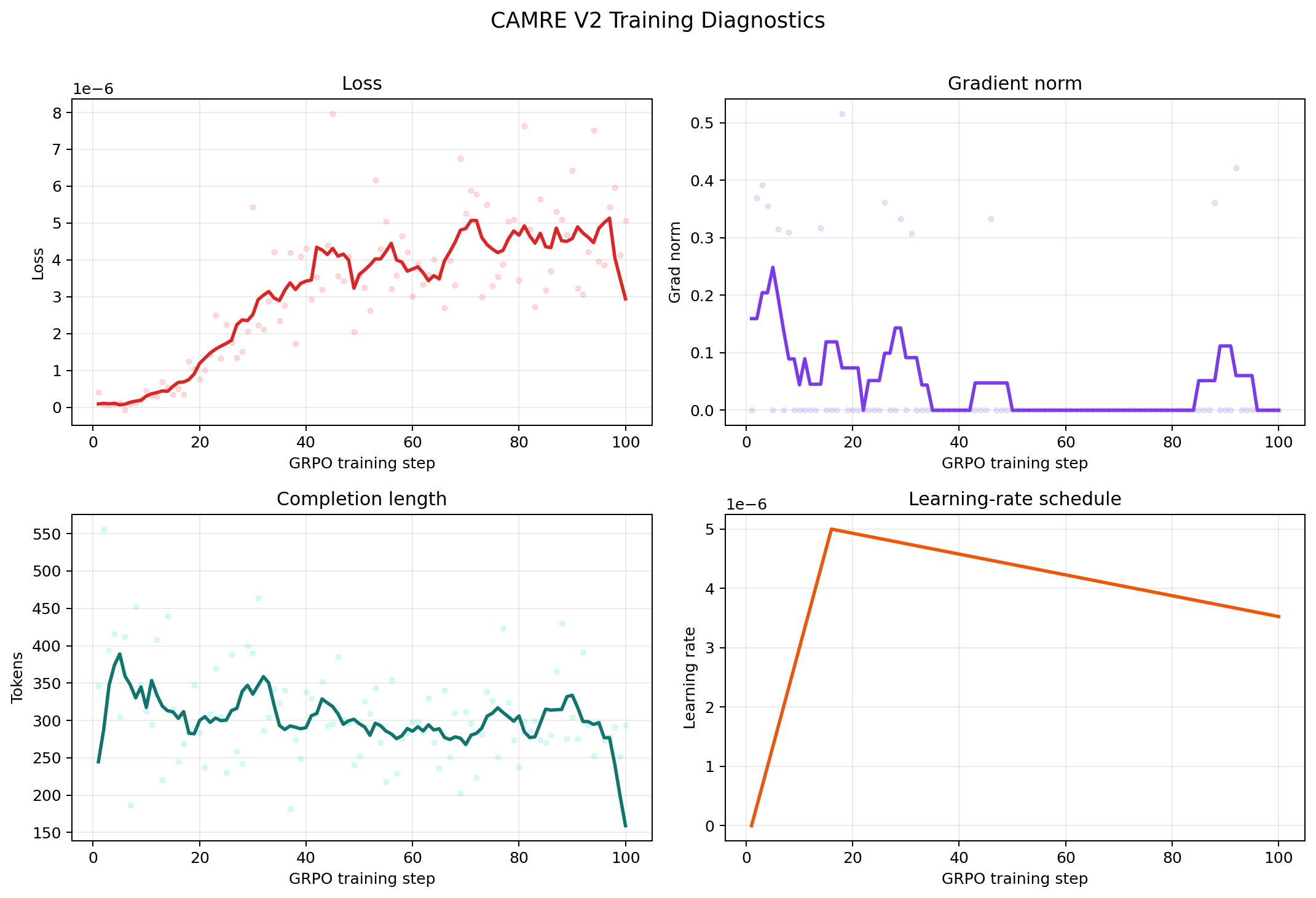
Training Diagnostics
Task Families
CAMRE currently ships three code/log-focused task families:
incident_cache_lookupnoisy_log_triage_summarybug_triage_and_repair_decision
Each scenario includes the V1 benchmark core, with V2 runtime extensions layered on top where appropriate:
- structured artifacts with segment-level salience
- seeded cache opportunities
- compression targets
- routing hints
- deterministic structured-answer ground truth
- V2 working-memory constraints
- V2 checkpoint policy
- V2 milestone graph
- V2 cascade-routing policy
Action Space
V1 Core Actions
read_artifactquery_cachecompress_contextroute_subtasksubmit_answerterminate_episode
V2 Extended Actions
The current deployed environment adds these long-horizon control actions on top of the V1 core:
hydrate_segmentscreate_checkpointhydrate_checkpointpurge_working_memory
Across both versions, the design goal is the same: make the control problem explicit instead of hiding retrieval, memory, and routing choices inside middleware.
Observation Surface
V1 exposes the core task, budget, cache, compression, and routing telemetry. The current V2 deployment extends that surface so the agent can additionally observe:
- task family, scenario title, and answer schema
- artifact manifest with access mode and preview handles
- latest tool result
- token and cost budgets
- cache statistics
- compression statistics
- routing history and confidence signals
- working-memory usage and loaded entries
- checkpoint manifest
- milestone progress counters
- reward components and guardrail events
Hidden state remains private inside the environment so the agent cannot directly inspect oracle truth, milestone conditions, or routing internals.
Reward Design
CAMRE uses a composite reward design across both versions.
V1 Reward Foundations
- terminal correctness
- partial progress
- action validity
- cache decision quality
- compression decision quality
- routing decision quality
- budget efficiency
V2 Additions
V2 keeps the V1 components and adds longer-horizon process supervision:
- milestone progress
- memory-management quality
- hydration efficiency
- routing-escalation quality
Guardrails penalize failure modes such as:
- invalid actions
- repeated loops
- unsafe purge behavior
- working-memory overflow
- checkpoint spam
- repeated routing without need
- critical-context loss during compression
Model Catalog
The frozen catalog lives in catalog.py and includes:
- open-source SLMs
- open-source LLMs
- closed-source SLMs
- closed-source LLMs
The catalog is based on real-world model identities and metadata, but runtime behavior is simulated so training and evaluation remain reproducible.
Runtime Architecture
The current deployed runtime is the V2 architecture, split into focused modules:
server/TokenOptEnv_environment.py- OpenEnv adapter and episode lifecycleepisode_runtime.py- internal per-episode mutable runtime statememory_manager.py- working memory, hydration, purge, and checkpointsmilestone_engine.py- hidden milestone tracking and milestone rewardsobservation_builder.py- public observation/state constructionsimulators.py- cache, compression, and routing simulationrewards.py- composite reward calculation and anti-cheat guardrailsscenario_store.py- seeded benchmark scenarios and graderstask_defs.py- scenario schemas and V2 config objectsmodels.py- OpenEnv-facing action, observation, and state models
Quick Start
from TokenOptEnv import ActionType, TokenOptEnvAction
from TokenOptEnv.server.TokenOptEnv_environment import TokenOptEnvEnvironment
env = TokenOptEnvEnvironment()
obs = env.reset(scenario_id="incident-medium-kafka-backpressure", seed=7)
obs = env.step(
TokenOptEnvAction(
action_type=ActionType.READ_ARTIFACT,
artifact_id="log-reconciler-5521",
)
)
print(obs.last_tool_result.payload["access_mode"])
print(obs.last_tool_result.payload["preview_segment_ids"])
obs = env.step(
TokenOptEnvAction(
action_type=ActionType.HYDRATE_SEGMENTS,
context_segment_ids=["log-reconciler-5521-s1"],
)
)
print(obs.working_memory.token_budget_used)
print(obs.milestones.achieved_ids)
Training Notebooks
The repo includes both versions of the training workflow:
notebooks/CAMRE_GRPO_Training.ipynb- original V1 GRPO notebooknotebooks/CAMRE_GRPO_Training_V2.ipynb- operational V2 notebook aligned to the public step-100 export flownotebooks/CAMRE_GRPO_Training_V2_Clean.ipynb- polished V2 notebook with explanatory markdown for reproducible reruns
In other words: V1 documents the initial benchmark/training path, and V2 documents the longer-horizon upgrade path.
Running the Server Locally
uvicorn server.app:app --reload --host 0.0.0.0 --port 8000
Repo Structure
TokenOptEnv/
|-- assets/
| `-- plots/
| |-- camre_v2_reward_progress.png
| `-- camre_v2_training_diagnostics.png
|-- Dockerfile
|-- __init__.py
|-- catalog.py
|-- episode_runtime.py
|-- memory_manager.py
|-- milestone_engine.py
|-- models.py
|-- notebooks/
| |-- CAMRE_GRPO_Training.ipynb
| |-- CAMRE_GRPO_Training_V2.ipynb
| `-- CAMRE_GRPO_Training_V2_Clean.ipynb
|-- observation_builder.py
|-- openenv.yaml
|-- pyproject.toml
|-- README.md
|-- rewards.py
|-- scenario_store.py
|-- simulators.py
|-- task_defs.py
|-- uv.lock
`-- server/
|-- __init__.py
|-- TokenOptEnv_environment.py
|-- app.py
`-- Dockerfile
Current Positioning
CAMRE as a project is positioned as a research benchmark first:
- deterministic enough for repeatable RL training
- realistic enough to study cost-aware inference control from V1 through V2
- explicit enough to expose routing, memory, checkpoint, and escalation decisions as learnable actions
- structured enough to support detailed reward decomposition and debugging
Public Artifact Policy
- Environment runtime: public and actively deployed in the Environment Space (currently the V2 runtime)
- Training workspace: hosted separately in the Training Space
- Model artifact: public adapter repo built around the exported step-100 CAMRE V2 checkpoint
This keeps the environment, training workflow, and model artifact separately reusable while still linking them together as one benchmark story that includes both the original V1 benchmark and the extended V2 runtime.
Notes
- The public runtime repo is intentionally lean. Some local-only utilities used during development may not be tracked here.
- The benchmark is designed to evolve while preserving comparability across scenario IDs and task families.